
Na różnych etapach rozwoju kariery chyba każdego specjalisty IT przychodzi czas, kiedy zadajemy sobie pytanie, czy to, co robię, faktycznie jest tak dobre jak tylko może być? Jestem przekonany, że osoby, które zwracają szczególną uwagę na jakość świadczonych przez siebie usług bądź oferowanych produktów mierzą staranność wykonania przez pryzmat pytania: Czy nie wstydzę się pod tym podpisać?
W tym artykule zebrałem moim zdaniem najlepsze praktyki pisania kodu źródłowego Apex jako programista technologii Salesforce. Usiądź wygodnie i sprawdź, czy stosujesz je wszystkie.
Jako pierwszą i kluczową w mojej ocenie umiejętnością świadczącą o tym, jak dobry kod piszesz, jest kwestia nazewnictwa poszczególnych jego elementów. Kwestia, która w oczach części społeczności programistów wydaje się być trywialna, tak naprawdę odgrywa kluczową rolę w zrozumieniu ogólnej koncepcji i nurtu myślowego, jaki wybrał autor kodu, aby osiągnąć konkretny cel.
Czasem można spotkać się z opinią, że dobrze napisany kod jest jak historia, którą nam ktoś opowiada albo jak dobra książka. I zanim przejdziesz dalej zastanów się, proszę, czy faktycznie tak nie jest?
Załóżmy prosty scenariusz: mamy sytuację, w której od ostatniej dokonanej zmiany na rekordzie Case’a minęło 72 godziny i checkbox IsOnHold__c nie jest zaznaczony, to zamknij Case’a i ustaw wartość OpenCasesNumber__c na powiązanym Accouncie na wartość o jeden mniejszą od obecnej. Wartość nie może być mniejsza od 0.
Tak wyglądałby kod, który spełnia opisane wymagania, ale autor kodu nie do końca zwraca uwagę na nazewnictwo metod i zmiennych:

Natomiast tak wyglądałby kod, w którym autor zwraca uwagę na nazewnictwo zmiennych i metod:

Mimo, że wywołanie jednego bądź drugiego kodu przyniesie ten sam rezultat, to ten drugi czyta się wygodniej, a nazwy sugerują, co metoda ma na celu oraz co poszczególne zmienne przechowują. Taki kod nie tylko łatwiej jest zrozumieć i utrzymywać, ale pokazuje również “klasę” osoby, która go napisała. Myślę, że jest część osób, która ma obawy czy ich kod aby przypadkiem nie wygląda… za prosto. Te osoby uspokajam i zapewniam – znacznie gorzej jest przesadzić w drugą stronę i oddać coś, co działa, ale jest trudne do zrozumienia i w efekcie cięższe w utrzymaniu.
W Salesforce, oprócz ogólnych zasad Clean Code, takich jak nazywanie zmiennych i metod notacją camelCase, a klas PascalCase, przyjęło się kilka dodatkowych rekomendacji, które warto stosować.
Rekomendacje dla zmiennych:
- unikaj stosowania słów generycznych, tj. var, variable, temp, value, data,
- ogranicz zawieranie nazwy typu zmiennej w jej nazwie, za wyjątkiem SObjectów,
- wybierz nazwę, która nie będzie budziła wątpliwości, co w danej zmiennej się znajduje,
- nie skracaj nadmiernie słów – newCase to dobry pomysł, podczas gdy newC już nie; uważaj na to szczególnie przy pętlach.

Rekomendacje dla metod:
- wybieraj nazwy, które dobrze opisują za co odpowiedzialna jest dana metoda,
- unikaj nadmiernych spójników w nazwach, np. “callAndDeserialize”, “getCaseOrNull”,
- nie łącz zbyt wielu słów w nazwie – od 1 do 3 słów to optymalna nazwa, nie powinniśmy przekraczać 4 słów,
- kieruj się zasadą, że dobra nazwa metody to taka, która opisuje akcję lub cel metody przy zachowaniu jasnego i opisowego wyrażenia napisanego w camelCasie.

Rekomendacje dla klas:
- stosuj koncepcję “serwisówek”, czyli łączenia nazwy SObject ze słowem Service, np. CaseService, OpportunityService
- sugeruj już w nazwie czy klasa wykorzystuje mechanizm “sharingów”: dla klasy, która go zachowuje i operuje w obrębie rekordów Account , dobrym pomysłem będzie AccountService, w przeciwnym przypadku AccountServiceNoShare
- warto wykorzystywać prefixy, gdy w ramach jednego repozytorium jest wiele projektów

Programowanie, jak wszystko dookoła nas, nie jest idealne i – choć przyjemnie byłoby mieć kod bez stałych wartości zapisanych na sztywno – to zamiast walczyć z faktem ich występowania lepiej jest znaleźć dla nich odpowiednie miejsce. Sprawdzi się w takiej sytuacji klasa, która będzie zawierać wyłącznie wartości stałe.
Stosując dobre praktyki nazewnictwa wiemy już, że nazwa Constants jest dobra, bo dokładnie określa jej przeznaczenie, a nazwa spełnia warunki notacji PascalCase’a.
Spójrzmy na przykład:

-
Słowem uzupełnienia – czasem zdarza się tak, że mamy dokładnie tę samą wartość, ale przeznaczoną do różnych zastosowań. Przykładem niech będzie status Draft – ta sama wartość będzie pasowała, gdy chcemy zaznaczyć status na obiekcie Contract jak również na obiekcie Case. Mimo, że wartość jest taka sama – sugeruję zrobić oddzielne stałe.
TriggerHandler to framework, który występuje w wielu wersjach, są opcje prostsze i bardziej złożone – implementowane zależnie od potrzeb projektowych. Zaletą tej konstrukcji jest to, że TriggerHandler jest:
- wysoce re-używalny (do każdego SObjectu),
- umożliwia mechanizm włączania i wyłączania konkretnych triggerów bez konieczności deploymentu na środowisko ( gdy je wyłączymy, to nie zapomnijmy ich włączyć)
- umożliwia model wymuszający (oparty o metody abstract) lub dobrowolny (oparty o metody virtual)
- umożliwia implementację modułu włączania / wyłączania konkretnego triggera z poziomu kodu w ramach transakcji.




Od razu odpowiem – jak najbardziej. Singleton to wzorzec projektowy znany ze znacznie starszych technologii niż Salesforce, ale przy programowaniu w Apex sprawdza się znakomicie.
Dlaczego?
- Ponieważ jest on bardzo skuteczny w oddalaniu widma “uderzenia” w limity, które obowiązują w ramach transakcji.
Singleton sprawdzi się w obiektach, które przechowują rzadko (bądź nie w ramach transakcji) zmieniające się dane. Przykładem może być obiekt User, RecordType, Profile, Custom Metadata i inne, własne, przechowujące na przykład dane konfiguracyjne. Nie warto natomiast korzystać z Singletona przy Accountach, Case’ach czy Oppkach, które stanowią fundament systemu.
Dlaczego?
- Singleton zakłada wyquerowanie danych raz, a potem zwracanie pobranych danych bez ich ponownego querowania, a w części sytuacji oczekujemy właśnie pobrania “świeżych” danych.
Najważniejsze korzyści to:
- wysoka uniwersalność (konstrukcja nie zmienia się dla różnych SObjectów),
- łatwy w implementacji,
- zapobiega nadmiernemu wykorzystaniu SOQL’ek w ramach transakcji.
Zwróćmy uwagę na ważną rzecz – na obrazku obok zaznaczono żółtą ramką prywatne pole klasy UserService, nazwane currentLoggedUser, które stanowi sens Singletona. Została do pola dodana adnotacja @TestVisible. Jej celem jest możliwość ustawienia w tym polu wartości null w sytuacji, gdy w ramach jednego Unit Testu chcemy pobrać informacje o Userze wykonującym daną akcję w ramach metody System.runAs().


Podzielę się z Wami żartem, który bardzo mi się spodobał: „czasem dzięki kilku godzinom debuggowania możemy zaoszczędzić kilka minut spędzonych na czytaniu dokumentacji”.
Najprawdopodobniej przynajmniej raz w miesiącu każdy z nas musi coś zdebuggować. W zależności od projektu proces ten może trwać krócej lub dłużej. Zakładam również, że znacie sytuację, gdy użytkownik mówi, że mu system nie działa, a gdy my próbujemy odtworzyć kroki, które wykonał, to następuje słynne, “u mnie działa”. Może się okazać, że nie mając informacji o tym, jakie dokładnie operacje, w jakiej sekwencji i z jakimi danymi wejściowymi wykonał użytkownik, błąd jest niemożliwy do odtworzenia. Powstaje niepewność czy kod na pewno jest odporny na błędy.
Wtedy na ratunek przychodzi Logger, który pozwala uzyskać cenniejsze informacje niż logi z konsoli deweloperskiej bez system debugów pozostawionych w kodzie na stałe.
Pomysłów na Logger jest wiele i każdy charakteryzuje się czymś innym. Istnieją gotowe paczki tj. NebulaLogger, ale można również wdrożyć własny Logger. Jeden z przykładów przedstawia poniższy rysunek:

Główne korzyści płynące ze stosowania Loggera to:
- Możliwość sterowania tym, jakie dane mają znajdować się w generowanym w systemie logu,
- Możliwość ustawienia, które obszary aplikacji podlegają logowaniu, a które nie,
- Przechowywanie logów jako rekordów z możliwością sterowania dostępem do nich i tym, jak zdefiniowany jest rekord loga,
- Możliwość przechwycenia informacji o działaniach użytkownika nawet, gdy w konsoli deweloperskiej nie jest włączone śledzenie działań tego użytkownika,
W przypadku podanego wyżej schematu dodatkowym atutem jest możliwość zalogowania loga do systemu nawet wtedy, gdy w kontekście triggera wykorzystamy metodę addError() – wynika to z zastosowania Platform Eventu.
Sam, co prawda, nigdy za konsolą pilota samolotu nie siedziałem, ale to miejsce przedstawiane jest jako panel z bardzo dużą liczbą przycisków, potencjometrów, wskaźników, diod i dźwigni.
Myślę, że prawdziwym majstersztykiem jest napisanie kodu w taki sposób, żeby wykonywanie jego poszczególnych fragmentów uzależnione było od ustawień w takim właśnie kokpicie. Podobne podejście zastosowano w TriggerHandlerze, gdzie sterowanie triggerem może odbywać się właśnie poprzez Custom Metadatę czy własny, customowy obiekt konfiguracyjny.
Warto chyba zastanowić się nad taką koncepcją. Przyjemnie byłoby móc napisać na tyle elastyczny kod, który pozwalałby z poziomu organizacji Salesforce sterować czy dane sekcje na stronie są widoczne czy nie, konfigurować per profil, rola w systemie czy kraj użytkownika. Podejście takie wymaga dodatkowego czasu na początku projektu, aby zainicjować obiekt konfiguracyjny i napisać do niego Singleton. Także każda nowa funkcjonalność wówczas zajmuje dodatkowe kilka minut, żeby móc ująć jej włączenie / wyłączenie w panelu kontrolnym. Biorąc jednak pod uwagę szerokie korzyści, warto ten czas zainwestować. Zwróci się w sytuacjach, gdy klient zmienia wymagania co do jakiejś funkcjonalności – zamiast usuwać kod, zmieniamy konfigurację w naszym “kokpicie”. Możliwość wdrożenia szybkiej zmiany z pewnością pokaże klientowi, że jesteśmy na każdą sytuację przygotowani.

Podstawową zasadą słyszaną w kontekście pisania kodu jest “Don’t repeat yourself”. To fakt, widok tego samego kodu wklejonego kilka razy w różnych miejscach w systemie budzi przestrzeń do pytań. W takich sytuacjach warto zastosować oddzielną metodę która będzie w stanie zadziałać przy delikatnie różnych danych wejściowych, na przykład dla różnych SObjectów.
Zaoszczędzone linie kodu przekładają się na mniejszą ilość kodu do napisania przy Unit Testach i oszczędności w użytych znakach kodu Apex z ustalonego limitu.

Zdarzają się nam wszystkim sytuacje, kiedy jakaś część system nie działa zgodnie z oczekiwaniami. Najczęściej w efekcie rekordy wymagają datafixu po naprawie niedziałającej funkcjonalności. Jest to szczególnie stresująca sytuacja, gdy incydent ma miejsce na środowisku produkcyjnym. Gdy wykorzystujemy triggery czasami powrót do danego stanu rekordu sprzed incydentu jest utrudniony, a nawet niemożliwy (szczególnie, gdy część pól nie jest lub nie może być śledzona).
Ostatnią rzeczą jakiej wtedy nam potrzeba jest to, żeby zaplanowane mechanizmy tła, flowy czy batche dodatkowo zmieniały rekord, który musimy przeanalizować i stworzyć plan naprawczy.
Aby zapobiec takim sytuacjom warto zastosować tzw. ByPass, dodatkowe pole (checkbox/picklista), którego rola sprowadza się do tego, że – gdy jest zaznaczone, to mechanizmy tła nie wprowadzają zmian na rekordzie, nawet jeśli są spełnione inne kryteria wejściowe.
Oczywiście decyzja o tym, jak taki ByPass miałyby działać, czy miałby dotyczyć wyłącznie operacji tła czy również triggerów oraz czy powinien być to checkbox czy picklista, pozostaje do decyzji programisty.
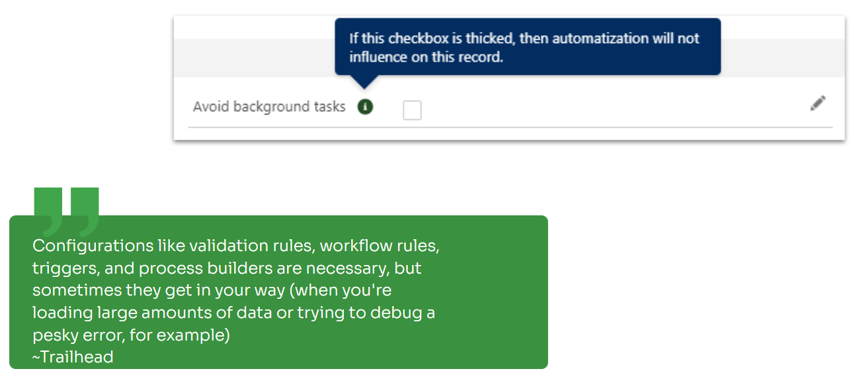
To podejście, podobnie jak Singleton, ma na celu odsunąć od nas zmorę limitów transakcyjnych Salesforce. Ten prosty pomysł najczęściej wykorzystywany jest w kontekście triggera. Zanim pobierzesz, sprawdź czy w ogóle jest to coś, czego szukasz.

O ile w dobrze prowadzonych projektach pytanie “Kto to zrobił?” pada rzadko albo wcale, to pytanie “Dlaczego coś działa tak, a nie inaczej” powinno być zadawane dość często.
Kluczem do połączenia kodu z wymaganiami mogą być commit messages, a im lepsza korelacja, tym łatwiej zrozumieć ciąg przyczynowo – skutkowy. Stąd w najlepszych praktykach programowania w Apex zaleca się stosowanie jasnego identyfikatora, który umożliwia lokalizację ticketu z wymaganiami w kodzie. Przykład: Jeśli realizujesz zadanie o identyfikatorze np. 1103, to dobrym pomysłem jest, aby Twój commit message wyglądał następująco: “1103 – [krótki opis tego, co zawiera commit]”.
Na koniec zebrałem jeszcze kilka rzeczy, których warto unikać pisząc kod Apexa:
- Hardcodowanie ID,
- Ignorowanie istnienia instrukcji try catch,
- DMLki i SOQLe w pętlach,
- Pobieranie szerszego zbioru danych niż jest potrzebny i iterowanie po nim zamiast stosowania klauzuli WHERE w zapytaniu SELECT,
- Brak konsekwencji w przyjętych koncepcjach projektowych,
- Zaciąganie długu technologicznego podyktowane motywem dostarczania większej ilości funkcjonalności,
- Pisanie nieefektywnych unit testów (pokrywających jedynie kod a nie sprawdzających funkcjonalność metod)
- Niestosowanie Data Factory w testach
Stosowanie dobrych praktyk pisania kodu Apex to nie jest sztuka dla sztuki, tylko realne rozwiązania, które służą zarówno programistom jak i końcowym użytkownikom aplikacji. Stosowanie ich niejednokrotnie wpływa na kondycję systemu, możliwość szybkiego reagowania na incydenty i ogólny performance aplikacji.
Ponadto, gdy weźmiemy sobie do serca wskazówki, czego należy się wystrzegać, to zyskamy kolejne podpowiedzi, jak pisać dobre jakościowe oprogramowanie w ekosystemie Salesforce.
Stosowanie best practices programowania APEX naprawdę nie jest trudne. Uczy efektywnego pisania kodu i zapobiega trudnościom z utrzymaniem kodu w przyszłości. Decyzja o tym czy je stosować nie powinna podlegać dyskusji, a w ramach współpracy projektowej powinniśmy ustalić które przyjmujemy, a które nie stanowią wartości dodanej przy budowaniu lub rozwijaniu konkretnego rozwiązania.
Szczęśliwego kodowania!
- Salesforce Developer
-
Salesforce Developer z ponad trzyletnim doświadczeniem, pasjonat optymalnych, zgodnych z zasadami rozwiązań. Posiada kilka certyfikatów Salesforce z zakresu programowania i konfigurowania platformy. Lubi wyzwania polegające na optymalizacji oprogramowania pod kątem wydajności i customer expirience. Prywatnie prawdziwy fan metodologii Agile, który stara się implementować ją w codzienności, człowiek, który chce dojść do wielkich rzeczy poprzez samorozwój. Lubi słuchać podcastów historycznych oraz zgłębiać wiedzę z zakresu psychologii.